CORRECTIV is working on a new AI tool
In the JournalismAI Fellowship, CORRECTIV developed the prototype for a new AI application within an international team of editors and developers.

Is artificial intelligence a threat to journalism and public discourse or does it serve the interests of a struggling media industry? Both is correct – depending on how the technology is used. The JournalismAI Fellowship Programme (JAIFP) at the Polis Institute of the London School of Economics brings together journalists and technologists from media organisations worldwide to explore solutions to improve journalism via the use of AI technologies. For the 2023 cohort of the programme, conducted with the support of the Google News Initiative, 32 journalists and technologists from 15 news organisations across the world have been selected – among them journalists from CORRECTIV. The fellows collaborated in six self-selected teams. CORRECTIV teamed up with India Today and Malaysiakini to leverage the power of Large Language Models for their newsrooms.
India Today: The news website India Today is a part of the India Today Group. In addition, the group operates a TV channel of the same name and includes numerous TV channels, online offerings and print publications. India Today’s fact-checking unit is a signatory to the IFCN. The organization was represented in the fellowship by the editors Piyush Aggarwal and Ankit Kumar.
Malaysiakini: Malaysiakini is an independent media company publishing in four languages (Malay, English, Chinese and Tamil). The news website is reaching an audience of 2.5 million. Editor Andrew Ong and fullstack engineer M. Vashiegaran represented the organization in the fellowship.
CORRECTIV: Founded in 2014, Correctiv is Germany’s first non-profit investigative newsroom. Ever since the organization diversified its activities. The fact-checking unit is a signatory to the IFCN and is EFCSN certified. Moreover, CORRECTIV strengthens media and information literacy through various projects. Caroline Lindekamp, project lead noFake, represented CORRECTIV in the fellowship as a team coordinator; the fullstack developers Jonas Schatz and Benjamin Werner partly supported the project.
THE VISION
The three different newsrooms from three different regions shared a common problem: They work with a lot of data for reporting which is difficult for the audiences to interact with – from election data to databases on misinformation and the economy, among others. The team envisioned an AI tool that should allow queries on the respective structured datasets in natural language, similar to interactions with ChatGPT.
In fact, the emergence of Large Language Models has inspired us to make journalistic output more interactive and enhance user experience. Transforming the way readers engage with data, media organisations tap into new target groups with consumption preferences beyond traditional journalism. Interactivity empowers users to explore data on their own terms. “Our goal is to make datasets ‘chat-able’. This can provide journalists, readers and researchers information at their fingertips. This helps us in our mission to hold the government accountable,” said M. Vashiegaran and Andrew Ong of MALAYSIAKINI.
THE USE CASES
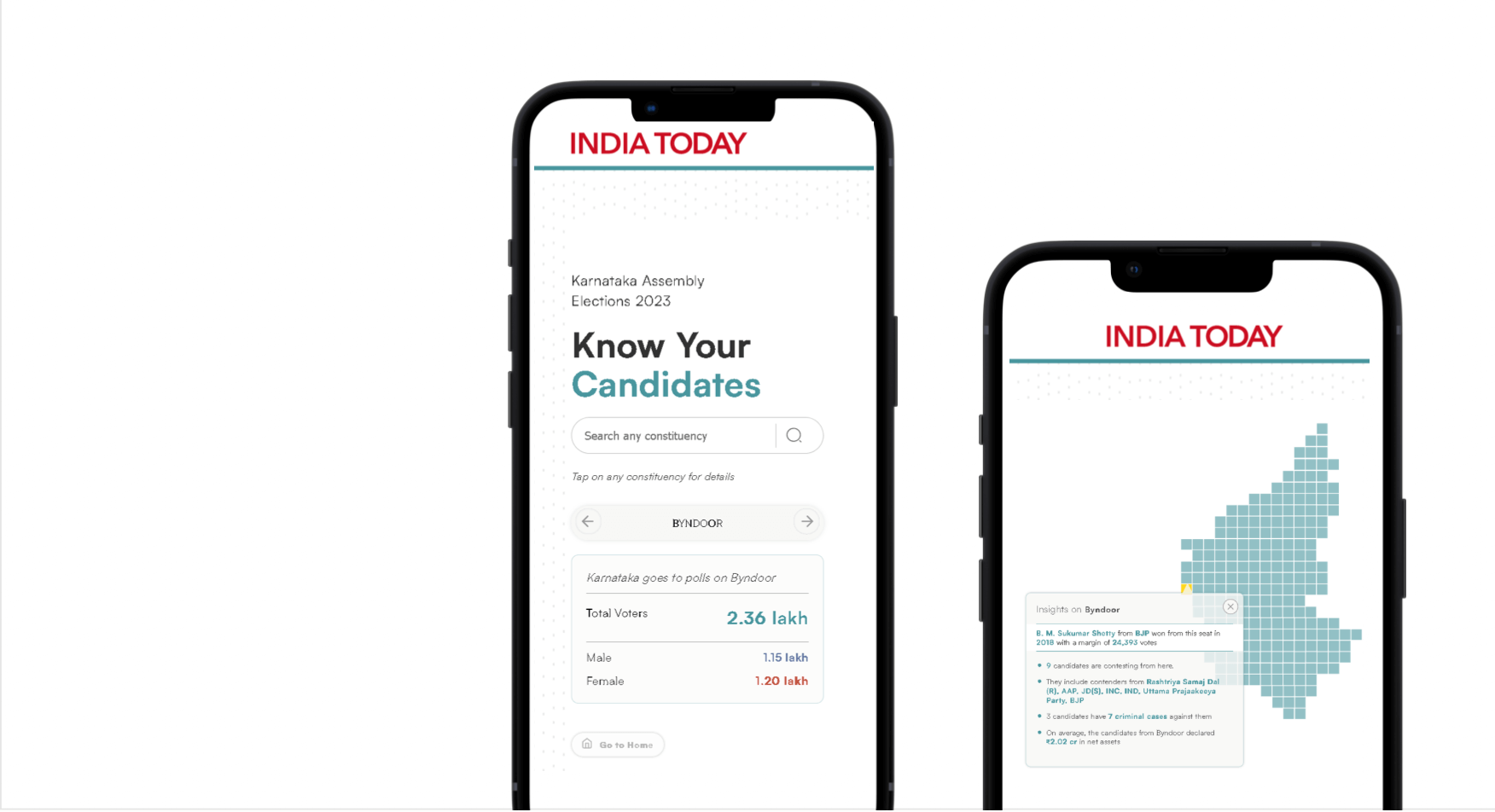
The project builds upon previous work of the three newsrooms: The organisations are involved in debunking activities and have relevant datasets in this field. At CORRECTIV, an editorial team debunks misinformation since 2017 and so far has produced around 3,000 fact-check articles. INDIA TODAY is equally involved in fact-checking and for the fellowship project also curates information about the upcoming general election in India in early 2024 – a milestone election for the nation’s democracy. “The Indian election is one of the biggest elections in the world. For instance, in 2019 general elections, there were approximately 8,000 candidates from 700 political parties to choose from,” said Piyush Aggarwal and Ankit Kumar from INDIA TODAY to outline the scope of the dataset. “For our existing election dashboards we always had to select information from the data, were facing design constraints and could only enable a one-way communication.”
In fact-checking, journalists are facing challenges of their own. “CORRECTIV disseminates its debunking results through various channels and in different formats to increase the outreach and also target audiences particularly vulnerable to misinformation,” said Caroline Lindekamp from CORRECTIV. “We also carry out prebunking and, with the CORRECTIV.Faktenforum, are building a community for people who are committed to countering disinformation and want to get actively involved in fact-checking themselves. For the users, interacting with our database of existing fact-checks via an LLM-based tool would be an important addition.”

CHALLENGES WHEN IMPLEMENTING LLMs
The team was aware of the varied risks of AI applications to journalism and wanted to offset weaknesses we know from generative AI-tools such as ChatGPT. They do not produce facts but predict language. Hence, their output might come in a credible guise but always carries the risk of producing misinformation — a result of so-called hallucination. The team faced more technical challenges.
Currently, there is a lot of talk about Large Language Models, mostly about the LLM of OpenAI, which became known with the user-friendly application ChatGPT. In fact, there are numerous such language models. When integrating them into an application one has to choose between paid offerings such as the OpenAI interface and open source models like Llama. In tests, Team Daisy achieved the best results with GPT and early success by making INDIA TODAY’s election dataset ‘chat-able’.
However, it became apparent that a universal framework that would work for both numbers-based datasets like election data and a text-based dataset was not viable. In addition to INDIA TODAY’s ElectionGPT, the team had to create a separate set of tools to work on CORRECTIV’s fact-check database.
Behind the scenes – the technology behind the tools
Backend ElectionGPT and FactcheckGPT of INDIA TODAY: The tool uses PostgreSQL as a database for both ElectionGPT and FactCheckGPT along with GPT-4 as a language model. INDIA TODAY also used GPT-3.5 initially, however, the performance of GPT-4 turned out much better.
Backend CORRECTIV.Checkbot of MALAYSIAKINI: CORRECTIV’s fact-check database was vectorised on MongoDB. User inputs (“claims”) are turned into embedded vectors and checked against the vector database. Matches are then filtered by using OpenAI’s chat completion function with a series of instructions. Finally, function calling is used to format the output in json format.
FROM ONE-WAY TO TWO-WAY COMMUNICATION
The CORRECTIV.Checkbot is in an internal testing phase before it will be made available for users in 2024.
How the CORRECTIV.Checkbot works in detail:
With advice from Replyr.ai’s Dylan Tan, the tech team of MALAYSIAKINI started experimenting with a vector database where one of the fields in CORRECTIV’s dataset was vectorized. When a user enters a claim to be checked against the vectorised field, the user input is also vectorised and matched against a database on Pinecone. This produced some undesirable results because this method was not able to evaluate whether matches were contextual. This is because the score which determines whether the match was high or low confidence was unreliable as well. Moreover, Pinecone is expensive.
In view of this, we moved to Mongodb which can perform vector similarity search and is cheaper compared to Pinecone. In addition, Mongodb can store both document and vector based data. We created a filter that will evaluate the five matches closest to the user’s input by using Open AI’s GPT4-turbo model, chat completion function and produce an output using function calling capabilities.In the Filter, Chat completion function were given series of instruction to choose the most relevant match to the user’s claim and also the fact-check article most up-to-date, in case the matched articles involve similar topics or subjects.
Finally, the LLM component of our program will craft a human-like response to the user with either a summary of the fact-check article along with a link to the full article, or inform the user that there was no match and our team will review their submission.
INDIA TODAY’s ElectionGPT has already been available in a beta version for the regional elections in the state of Uttar Pradesh, India’s most populous state. In 2024 users voters can seek information in natural language for the national elections. The team also adapted their tool to allow queries on a database of fact-checks they retrieved from the claim review database and plans to apply the tool to other datasets like sports news or crime reporting.