CORRECTIV arbeitet an einem neuen KI-Tool
Im JournalismAI Fellowship arbeitete CORRECTIV in einem internationalen Team an einem neuen KI-Tool. Ihr Ziel: komplexe Datensätze „chatbar“ machen. Den Prototyp stellten sie beim JournalismAI Festival vor.

Ist Künstliche Intelligenz (KI) eine Bedrohung für den Journalismus und die öffentliche Debatte oder eröffnet sie einer Branche unter Druck Innovationspotenziale? Beides ist richtig – je nachdem, wie die Technologie eingesetzt wird. Um KI-Anwendungen entsprechend journalistischen Standards zu entwickeln, bringt das JournalismAI Fellowship Programme am Polis Institute der London School of Economics Redakteurinnen und Developer aus Medienorganisationen weltweit zusammen. Die Google News Initiative unterstützt das Programm. Für den diesjährigen Jahrgang wurden rund 30 Bewerber und Bewerberinnen von 15 Medienorganisationen aus aller Welt ausgewählt – darunter auch CORRECTIV-Mitarbeiter. Die Fellows arbeiteten in sechs selbstgewählten Teams zusammen. Caroline Lindekamp aus unserem noFake-Team hat sich mit India Today und Malaysiakini im Team Daisy zusammengetan, um sogenannte Large Language Models in Anwendung zu bringen. CORRECTIV-Developer Benjamin Werner hat das Frontend entwickelt.
India Today: Die Nachrichten-Webseite India Today ist Teil der India Today Group, die auch einen gleichnamigen Fernsehsender und zahlreiche weitere Medienangebote umfasst. Die Faktencheck-Redaktion von India Today gehört wie CORRECTIV zum International Fact-checking Network (IFCN). In dem Fellowship war India Today durch die Redakteure Piyush Aggarwal und Ankit Kumar vertreten.
Malaysiakini: Malaysiakini ist ein unabhängiges Medienunternehmen, das in vier Sprachen (Malaiisch, Englisch, Chinesisch und Tamilisch) veröffentlicht. Die Nachrichten-Website erreicht ein Publikum von 2,5 Millionen Menschen. Der Redakteur Andrew Ong und der Fullstack-Developer M. Vashiegaran vertraten die Organisation in dem Fellowship.
CORRECTIV: CORRECTIV startete 2014 als Deutschlands erste gemeinnützige Investigativredaktion. Seitdem haben wir unsere Aktivitäten diversifiziert – etwa mit CORRECTIV.Faktencheck oder Abteilungen für Medien- und Informationskompetenz wie der Reporterfabrik. Caroline Lindekamp, Projektleiterin noFake, vertrat CORRECTIV bei JournalismAI als Teamkoordinatorin; die Fullstack-Entwickler Jonas Schatz und Benjamin Werner unterstützten das Projekt.
Die Vision
In Team Daisy sind Journalisten und Developer aus drei Redaktionen aus drei unterschiedlichen Weltregionen vertreten. Sie brachte ein gemeinsames Problem zusammen: Wie können sie Recherchen und Archivdatenbanken für ihr jeweiliges Publikum besser zugänglich machen? Mit einer KI-Anwendung wollten sie Abfragen in natürlicher Sprache aus den jeweiligen Datensätzen ermöglichen – eine User Experience ähnlich wie bei ChatGPT.
Large Language Models (LLM oder große Sprachmodell) entwickeln sich rasant und Endnutzeranwendungen wie ChatGPT und Bing Chat haben die Technologie massentauglich gemacht. Die Reporterfabrik von CORRECTIV hat auf Basis eines großen Sprachmodells die Wolf-Schneider-KI an den Start gebracht, und der Fortschritt in dem Bereich inspirierte auch Team Daisy dazu, journalistische Inhalte interaktiver zu gestalten. Über solche alternativen Ausspielarten für ihre Inhalte erschließen Medien neue Zielgruppen. Informationen werden nach individuellen Vorstellungen und jenseits von traditionellen Darstellungsformen zugänglich. „Unser Ziel ist es, Datensätze chatbar zu machen. Dadurch können wir Journalistinnen und Lesern maßgeschneiderte Informationen liefern“, sagen M. Vashiegaran und Andrew Ong von Malaysiakini.
Die Anwendungsbeispiele
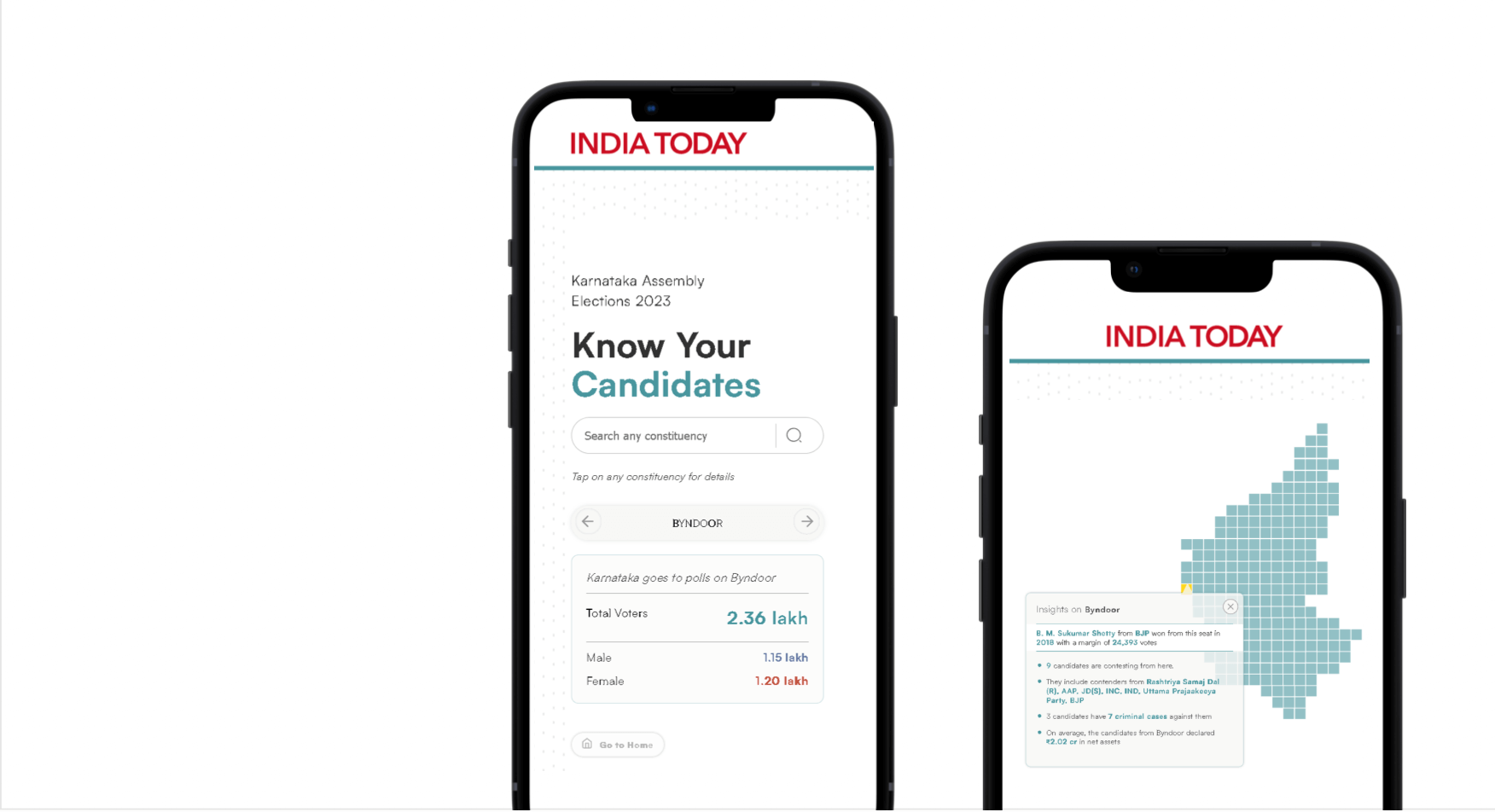
Das Projekt baut auf der bisherigen Arbeit der drei Organisationen auf: Alle beschäftigen eigenständige Faktencheck-Redaktionen und verfügen über relevante Datensätze in diesem Bereich. CORRECTIV.Faktencheck betreibt seit 2017 Debunking und hat bisher mehr als 3.000 Artikel veröffentlicht. India Today brachte in das JournalismAI-Programm zudem einen umfangreichen Datensatz zu den bevorstehenden Parlamentswahlen in Indien ein. „Die Wahl in Indien in 2024 ist wegweisend und eine der größten Wahlen weltweit. Vor fünf Jahren standen rund 8.000 Kandidaten von 700 politischen Parteien zur Auswahl“, sagen Piyush Aggarwal und Ankit Kumar von India Today und geben so einen Eindruck von dem Umfang des Datensatzes“. Bisher haben wir die Daten in Dashboard aufbereitet. Die Nachteile: Wir mussten immer ordentlich selektieren und konnten nur eine einseitige Kommunikation ermöglichen“.
CORRECTIV.Faktencheck veröffentlicht Recherchen nicht nur in Artikeln, sondern verbreitet die Informationen auf ganz verschiedenen Wegen und in unterschiedlichen Formaten. „So wollen wir die Reichweite steigern und auch die erreichen, die besonders anfällig für Manipulationsversuche durch Falschbehauptungen sind. Wir betreiben zudem Prebunking und bauen mit dem CORRECTIV.Faktenforum eine Community auf, in der sich jeder gegen Desinformation engagieren kann“, sagt Caroline Lindekamp. „Ein Tool, das User-Abfragen aus unserem Faktencheck-Datensatz in natürlicher Sprache ermöglicht, wäre ein weiterer Weg, um mehr Fakten in die öffentliche Debatte zu bringen.“

Die Herausforderungen
Team Daisy war sich den Risiken von KI-Anwendungen im Journalismus bewusst und wollte die Schwächen ausgleichen, die wir von generativen KI-Tools wie ChatGPT kennen. Sie haben kein Verständnis von Wahrheit, sondern reihen Wörter basierend auf Wahrscheinlichkeiten aneinander. So kommen die Ergebnisse zwar in glaubwürdigen Gewand daher, enthalten aber immer wieder auch Fehlinformationen. Es handelt sich dabei um sogenannte Halluzination.
Ein weiterer Knackpunkt war die Kostenfrage: Ist derzeit von einem großen Sprachmodell die Rede, geht es meist um das LLM von OpenAI, das durch die benutzerfreundliche Anwendung ChatGPT bekannt wurde. Es ist aber nur eines von vielen solcher Sprachmodelle – darunter kostenpflichtige Angebote wie das von OpenAI und Open-Source-Modelle wie etwa Llama. Team Daisy verglich genau diese beiden Modelle miteinander und erzielte mit GPT von OpenAI die besseren Ergebnisse.
Der Datensatz zu den indischen Wahlen wurde schnell „chatbar“. Universell war die Anwendung aber entgegen der ursprünglichen Erwartungen nicht. Der Datensatz zu den Wahlen war vor allem zahlenbasiert: Wie viele Kandidaten? Wie viele Stimmen? Wie hoch die Anteile? Faktenchecks überprüfen zwar regelmäßig Zahlenangaben auf ihre Richtigkeit, die Faktencheck-Datenbank ist aber vor allem textbasiert. Die Artikel liefern Kontext und Informationen, wo Falschbehauptungen verzerren oder zu kurz greifen. Um diesen Fundus für Nutzerabfragen zu öffnen, brauchte es einen neuen Ansatz und das Team entwickelte ein zweites Backend für den CORRECTIV.Checkbot.
Behind the scenes – das Backend hinter den Tools:
Backend ElectionGPT von India Today: Das Tool verwendet PostgreSQL als Datenbank und nutzt das Large Language Modell GPT-4 von OpenAI. INDIA TODAY testete zunächst die Version GPT-3.5, doch die Leistung von GPT-4 erwies sich als wesentlich besser.
Backend CORRECTIV.Checkbot von Malaysiakini: Die Faktencheck-Datenbank von CORRECTIV wurde auf MongoDB vektorisiert. Nutzereingaben wandelt das Tool ebenfalls in Vektoren um und gleicht sie mit der Vektordatenbank ab, in der alle Faktenchecks von CORRECTIV gesammelt sind. Übereinstimmungen werden dann mit Hilfe der Chatvervollständigungsfunktion von OpenAI mit einer Reihe von Anweisungen, sogenannten Prompts, gefiltert. Am Ende stehen die automatisierten Antworten, die im json-Format formatiert sind.
Von einseitiger zu wechselseitiger Kommunikation
Der CORRECTIV.Checkbot befindet sich in einer internen Testphase, bevor er im Jahr 2024 den Nutzern zur Verfügung gestellt wird. Den Prototyp präsentierte CORRECTIV beim JournalismAI Festival im Dezember 2023 vor einem internationalen Publikum.
So funktioniert der CORRECTIV.Checkbot im Detail
Andrew Ong und M. Vashiegaran von Malaysiakini wollten die CORRECTIV-Faktenchecks mithilfe einer Vektordatenbank ‘chatbar’ machen. Die rund 3.000 Artikel legten sie entsprechend ab; Nutzeranfragen sollte das Tool ebenfalls vektorisieren und mit der Datenbank abgleichen. In einem ersten Experiment übertrug das Team einen kleineren Testdatensatz zu Pinecone. Doch diese Vektordatenbank brachte einige unerwünschte Ergebnisse, weil sie Übereinstimmungen zwischen Datenbank und eingehenden Fragen nicht kontextbezogen abgleichen konnte. Außerdem ist Pinecone vergleichsweise teuer.
Das Team wechselte zu MongoDB, das vektorbasierte Ähnlichkeitssuche durchführen kann und günstiger als Pinecone ist. Zudem speichert MongoDB dokument- ebenso wie vektorbasierte Daten.
Entscheidend für das Funktionieren des CORRECTIV.Checkbots ist neben der Vektordatenbank ein eigens entwickelter KI-Filter. Er wertet die fünf besten Übereinstimmungen zwischen Nutzeranfrage und Datenbank etwa nach Relevanz und Aktualität aus. Dafür nutzen die Developer GPT-4, die jüngste Version des OpenAI-Sprachmodells, und die Chat-Vervollständigungsfunktion von OpenAI. Schließlich formuliert die LLM-Komponente des Tools eine Antwort. Sie liefert Usern entweder eine Zusammenfassung des Faktencheck-Artikels mit dem Link zum vollständigen Artikel oder legt offen, dass es keine Übereinstimmung gab.
Das Tool ElectionGPT von India Today war in einer Beta-Version bereits für die Regionalwahlen im Bundesstaat Uttar Pradesh, Indiens bevölkerungsreichstem Bundesstaat, verfügbar. Bei den landesweiten Wahlen im Jahr 2024 können Wählende Informationen zu den tausenden Kandidaten in natürlicher Sprache über ElectionGPT abrufen. Die Technologie soll zudem so weiterentwickelt werden, dass Abfragen aus verschiedenen weiteren Datensätzen möglich sind – wie Sportnachrichten oder Strafberichterstattung.